
查询优化器

所有现代数据库都使用基于成本的优化(Cost Based Optimization,CBO)来优化查询。其思路是,为每一个操作添加一个成本,通过使用成本最低的操作链降低查询成,最终获得结果。
为了弄清楚成本优化器是如何工作的,我觉得最好的方法是“感受”这个任务背后的复杂性。在这部分,我将表述连接两张表的三种通用方法,我们很快就会看到每一个简单的连接查询都是一个优化的噩梦。在此之后,我们将看到真正的优化器是如何进行这个工作的。
对于这些连接,我着眼于它们的时间复杂度,但是数据库优化器会计算其 CPU 成本、磁盘 I/O 成本以及所需内存。时间复杂度和 CPU 成本的区别在于,前者是非常粗略的(对于那些像我一样懒的人来说)。对于 CPU 成本,我需要计算每一个操作,比如一次加法,一条“if 语句”,一次乘法,一次便利等。另外:
- 每一条高级代码操作都需要几条低级 CPU 操作。
- 对于 Intel Core i7、Item Pentium 4 或者 AMD 的 CPU 而言,每一个 CPU 操作的成本都不相同(其术语是 CPU 周期)。换句话说,CPU 操作的成本取决于 CPU 架构。
使用时间复杂度更简单(至少对于我来说是这样),使用时间复杂度我们依然能够获得 CBO 的概念。有时我也会提到磁盘 I/O,因为这也是一个重要概念。时刻记住,瓶颈在磁盘 I/O 所消耗的时间,而不是 CPU 消耗的。
索引
在我们介绍 B+ 树的时候,我们讨论过索引。记住,索引已经排好序了。
仅供参考:数据库还有其它类型的索引,比如位图索引(bitmap indexes)。它们与 B+ 树索引消耗的 CPU 周期、磁盘 I/O 和内容都不相同。
另外,如果可以改善执行计划的成本,很多现代数据库可以为当前插件动态创建临时索引。
访问路径
在应用连接运算符之前,首先你需要获得数据。下面是你能够如何获得数据。
注意:由于访问路径真正的问题在于磁盘 I/O,因此我不会过多讨论时间复杂度。
完整扫描
如果你阅读过执行计划,你一定见过完整扫描(full scan,或者就叫 scan)这个词。完整扫描就是数据库读取整张表或索引。考虑到磁盘 I/O,很明显,对于整张表的完整扫描的成本要远远高于对于索引的完整扫描。
范围扫描
其它类型的扫描有索引范围扫描(index range scan)。当你使用谓词,比如“WHERE AGE > 20 AND AGE <40”时,就会使用索引范围扫描。
当然,为了使用索引范围扫描,你需要在 AGE 字段添加索引。
在前面部分,我们已经了解到,范围查询的时间成本可能会有 log(N) +M,其中,N 是索引数据量,M 是落在这个范围的行数的估计值。多亏了统计数据,N 和 M 都是已知的(注意,M 就是谓词 AGE >20 AND AGE<40 的选择率)。另外,对于范围扫描,你不需要只读完整的索引,因此要比完整扫描的磁盘 I/O 成本小得多。
唯一扫描
如果你只需要从索引获取一个值,可以使用唯一扫描(unique scan)。
通过 row id 访问
大多数时间,如果数据库使用索引,它就得找到关联到索引的那些行。为了达到这一目的,数据库会使用 row id 访问。
例如,如果你的语句如下:
SELECT LASTNAME, FIRSTNAME from PERSON WHERE AGE = 28
如果 age 列有索引,优化器会使用索引找到所有 28 岁的人,然后会请求表中关联的那些行。这是因为索引只包含了年龄的信息,但是你却想要获取 lastname 和 firstname。 但是,如果你的语句如下:
SELECT TYPE_PERSON.CATEGORY from PERSON, TYPE_PERSON WHERE PERSON.AGE = TYPE_PERSON.AGE
PERSON 的索引用于连接 TYPE_PERSON,但是 PERSON 表却不会使用 row id 访问,因为你并没有请求这个表的数据。
对于少量访问,这是可行的,但这个操作的真正问题在于磁盘 I/O。如果你需要通过 row id 访问很多数据,数据库可能会选择使用完整扫描。
其它路径
我并没有阐述所有访问路径。如果你想了解更多,可以阅读 Oracle 文档。对于其它数据库,文档的名字可能会有歧义,但是其背后的原理是相通的。
连接运算符(join)
现在我们知道了如何获得数据,然后,让我们将数据连接起来!
我会介绍三种通用连接运算符:归并连接、哈希连接和嵌套循环连接。但在此之前,我需要介绍一个新的术语:内关系(inner relation)和外关系(outer relation)。一个关系可以是
- 一个表
- 一个索引
- 来自上一步操作的中间结果(例如上一个连接的结果)
当你连接两个关系时,连接算法会分别管理两个关系。在本文剩下的部分,我会假设:
- 外关系是左数据集
- 内连接是右数据集
例如,A JOIN B 是 A 和 B 的连接,其中,A 是外连接,B 是内连接。
大多数情况下,A JOIN B 的成本与 B JOIN A 并不相同。
在这一部分,我同样假设外连接有 N 个元素,内连接有 M 个元素。时刻记住,真正的优化器可以通过统计知道 N 和 M 的值。
注意,N 和 M 是联系的基数。
嵌套循环连接(nested loop join)
嵌套循环连接是最简单的一个。
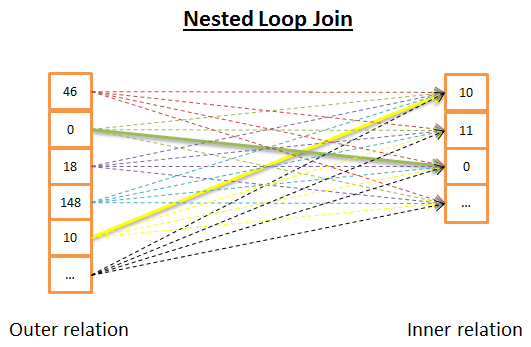
其思路是:
- 对于外关系的每一行
- 检查内关系中的所有行,看是不是有行能够匹配
伪代码如下:
nested_loop_join(array outer, array inner)
for each row a in outer
for each row b in inner
if (match_join_condition(a, b))
write_result_in_output(a, b)
end if
end for
end for
因为这里有两层循环,所以时间复杂度是 O(N*M)。
从磁盘 I/O 方面,对于外关系 N 行的每一行,内层循环都需要从内关系读取 M 行。这个算法需要从磁盘读取 N + N * M 行。但是,如果内关系足够小,那么就可以把所有关系放在内存,这样就只需要 M +N 次读取。根据这样的修改,内关系必须是最小的一个,因为只有这样才有更多机会放入内存。
从时间复杂度方面,这样并没有什么不同,但是从磁盘 I/O 方面,这种方式只需要读取两种关系一次。
当然,内关系可以替换为索引,这样对磁盘 I/O 更有利。
由于这个算法非常简单,对于那些不能完全读入内存的内关系而言,还有一个对磁盘 I/O 更友好的版本。其思路是这样的:
- 不是一行一行读取关系
- 按照批次读取关系,在内存中始终保存两个批次的行(每个关系都保留 2 个批次)
- 在两个批次内部比较行,保留匹配的行
- 然后,从磁盘加载新的批次,再进行比较
- 如此进行下去,知道没有批次可供加载
下面是算法伪代码:
// 改进版本,减少磁盘 I/O。
nested_loop_join_v2(file outer, file inner)
for each bunch ba in outer
// 现在 ba 在内存中
for each bunch bb in inner
// 现在 bb 在内存中
for each row a in ba
for each row b in bb
if (match_join_condition(a,b))
write_result_in_output(a,b)
end if
end for
end for
end for
end for
使用这个版本,时间复杂度相同,但是磁盘访问次数有所减少:
- 之前的版本,算法需要 N + N * M 次磁盘访问(每次访问读取一行)
- 新的版本,磁盘访问数变为 number_of_bunches_for(outer) + number_of_ bunches_for(outer) * number_of_ bunches_for(inner)
- 增加每一批次的大小,就能降低磁盘访问次数
注意:虽然每一次磁盘访问都可以加载比上述算法更多的数据,但是由于数据是顺序访问的(机械硬盘真正的问题是获得第一组数据所需时间),因此影响并不会很大。
哈希连接
哈希连接要比嵌套循环连接复杂得多,但是在很多情形下,它的性能要比后者好得多。
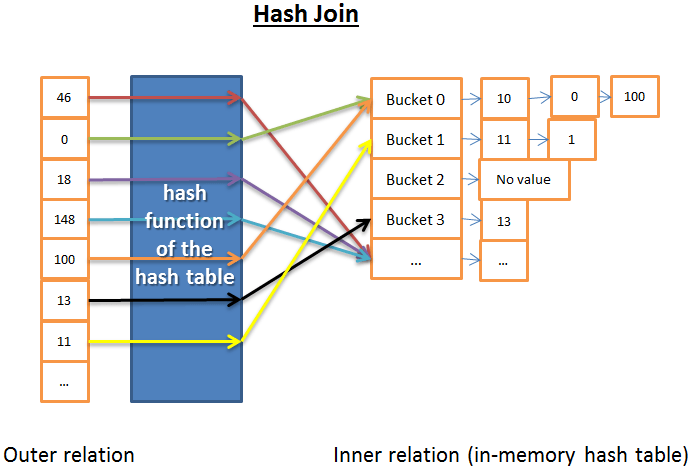
哈希连接的思路是:
- 从内关系获取所有元素
- 构建内存中的哈希表
- 依次获取外关系中的所有元素
- 计算每一个元素的哈希值(使用哈希表的哈希函数),找到与内关系关联的桶
- 检查桶中元素和外表中的元素是不是匹配
关于时间复杂度,我需要作一些假定以简化问题:
- 内关系分为 X 个桶
- 对于两个关系,哈希函数都可以均匀地散列哈希值。换句话说,这些桶的大小相同
- 外关系中的一个元素与桶中所有元素的匹配过程消耗只与桶中的元素数目有关
其时间复杂度是 (M/X) * N + cost_to_create_hash_table(M) + cost_of_hash_function*N
如果哈希函数创建足够小的桶,那么,时间复杂度就是 O(M+N)。
下面的哈希连接的版本对内存更友好,但是不利于磁盘 I/O。这一次:
- 同时计算内关系和外关系的哈希表
- 将计算出的哈希值存入磁盘
- 然后按照桶依次比较两个关系(现将一个加载到内存,然后依次读取另外一个)
归并连接
归并连接是唯一获得排序结果的连接。
注意:在这个简化的归并连接中,不存在内表或外表;它们的角色是一致的。但是,实际实现是有区别的,例如,当处理复制时。
归并连接可以分为两步:
- (可选的)排序连接操作:两个输入都按照连接键进行排序
- 归并连接操作:将排好序的输入合并在一起
排序
我们已经讨论了归并排序,在这个情形下,归并排序是一个不错的算法(但是如果内存不是问题的话,这并不是最好的算法)。
但是,有时数据集已经排好序了,例如:
- 表自然地排序了,例如在连接条件上使用索引组织的表
- 如果在连接条件上,这个关系是一个索引
- 如果这个连接应用在一个中间结果上,而这个中间结果已经在查询处理阶段排好序了
归并连接
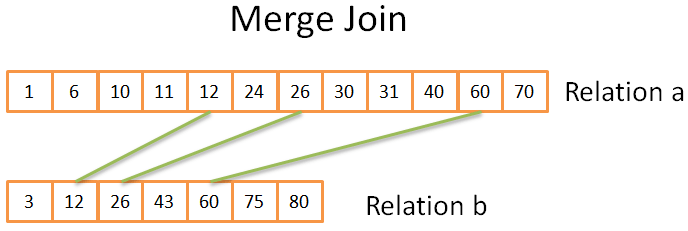
这一步非常像我们之前见过的归并排序的归并操作。但是这一次我们并不是从每个关系中取出每一个元素,而是从每个关系中取出相同元素。其思想是:
- 比较两个关系中的当前元素(第一次时,当前元素就是第一个元素)
- 如果相同,将两个元素放进结果集,然后获取两个关系中的下一个元素
- 如果不相同,从较小元素所在关系中取出下一个元素(因为下一个元素可能会相同)
- 重复以上 3 步,直到其中一个关系到达最后一个元素
因为两个关系都是排好序的,因此这种操作是可行的。你不需要在这些关系中“后退”。
这个算法是一个简化版本,因为它没有处理两个数组中相同数据出现多次的情况(也就是多次匹配)。真实的版本会更复杂一些,但也不会复杂太多,因此我选择了一个相对简单的版本。
如果两个关系都已经排好序,那么时间复杂度就是 O(N+M)。
如果两个关系都需要排序,那么时间复杂度就是两个关系排序的消耗:O(N * Log(N) + M * Log(M))。
对于计算机专业技术人员,下面是一个能够处理多次匹配的可行算法(虽然我也不是 100% 确保算法正确性):
mergeJoin(relation a, relation b)
relation output
integer a_key:=0;
integer b_key:=0;
while (a[a_key]!=null or b[b_key]!=null)
if (a[a_key] < b[b_key])
a_key++;
else if (a[a_key] > b[b_key])
b_key++;
else //Join predicate satisfied
//i.e. a[a_key] == b[b_key]
//count the number of duplicates in relation a
integer nb_dup_in_a = 1:
while (a[a_key]==a[a_key+nb_dup_in_a])
nb_dup_in_a++;
//count the number of duplicates in relation b
integer dup_in_b = 1:
while (b[b_key]==b[b_key+nb_dup_in_b])
nb_dup_in_b++;
//write the duplicates in output
for (int i = 0 ; i< nb_dup_in_a ; i++)
for (int j = 0 ; i< nb_dup_in_b ; i++)
write_result_in_output(a[a_key+i],b[b_key+j])
a_key=a_key + nb_dup_in_a-1;
b_key=b_key + nb_dup_in_b-1;
end if
end while 哪个最好?
如果有最好的连接方式,就不会有这么多种了。这个问题很难回答,因为有很多因素在里面:
- 可用内存总数:没有足够了内存,就基本可以跟强大的哈希连接说拜拜了(至少对完全内存中的哈希连接)
- 两个数据集的大小:例如,如果你有一张大表和一个很小的表,那么,嵌套循环连接要比哈希连接快一些,因为哈希连接需要计算哈希值。如果你的两张表都很大,那么,嵌套循环连接会消耗非常多的 CPU。
- 是不是有索引:对于归并连接,两个 B+ 树索引绝对是一个好主意。
- 如果结果需要排序:即使你的数据集没有排序,你还是可能想使用代价昂贵的归并连接(使用排序),因为最终结果是排好序的,你可以将这个结果交给另外的归并连接(或者是由于查询语句使用 ORDER BY/GROUP BY/DISTINCT 等隐式或显式要求了结果排序)。
- 如果关系已经排好序:这种情况下,归并连接是最好的选择。
- 你正在使用的连接类型:是不是 equijoin (例如 tableA.col1 = tableB.col2)?是不是 inner join、outer join、cartesian product 或者 self-join?某些连接不适用与特定情形。
- 数据的分布:如果连接条件中的数据是不均衡的(skewed),例如,你需要使用人名中的姓氏连接,但是很多人都有相同的姓,使用哈希连接就是一场灾难,因为哈希函数计算出来的桶是非常不均衡的。
- 如果你需要在多线程或多进程情形下进行连接。
更多信息,可以阅读 DB2、ORACLE 或 SQL Server 的文档。

2 评论
可以讲讲数据库怎么设计还有优化的吗?讲些例子也行,对这方面也很有兴趣
数据库设计一般需要结合实例,最基本的可以按照设计范式。参考下有关设计范式的相关内容。